
На заметку DevOps инженерам: дебажим Linux с помощью BPF

В прошедшие выходные в Караганде прошла конференция DevCorn 2023 для разработчиков, проджект-менеджеров, инженеров, QA-специалистов и тех, кто начинает карьеру в IT. Одним из спикеров был Аскар Сабыров, Server/laaS Lead Aitu.Cloud компании BTS Digital. Аскар поделился с участниками своим опытом работы BPF в среде Linux, чтобы они могли глубже изучить современные средства откладки Linux.
Аскар Сабыров, Server/laaS Lead Aitu.Cloud компании BTS Digital
Роль инженера DevOps заключается в обслуживании и управлении Linux средой, обеспечивая ее бесперебойную и эффективную работу. Однако даже при тщательном планировании и управлении в среде Linux могут возникать проблемы, для выявления и устранения которых требуется отладка, когда стандартные утилиты (top/ps/iostat/etc) не могут дать исчерпывающих ответов. Именно здесь такие инструменты, как BPF, могут оказать неоценимую помощь в мониторинге и анализе производительности вашей системы.

Отладка или debugging — это процесс выявления и устранения проблем или ошибок в программных системах. Это критически важная часть разработки и эксплуатации программного обеспечения, поскольку она помогает гарантировать, что приложения и системы функционируют так, как ожидается.
Прежде чем перейти к рассмотрению особенностей отладки Linux с помощью BPF, давайте сначала определим, что мы понимаем под «средой Linux». Под средой Linux понимаются программные и аппаратные компоненты, составляющие операционную систему Linux, включая ядро, системные библиотеки и пользовательские приложения.
Как инженеру DevOps, понимание того, как отлаживать Linux с помощью BPF, может помочь вам быстро и эффективно выявлять и устранять проблемы в вашей системе. В этом материале мы рассмотрим, как BPF можно использовать для отладки Linux, выделим его плюсы и минусы, а также ограничения, о которых вы должны знать.
Что такое BPF
BPF, или Berkeley Packet Filter — это виртуальная машина, работающая в ядре Linux. BPF первоначально разработана для фильтрации сетевых пакетов, впоследствии была расширена на другие области, такие как трассировка и профилирование, и получила название eBPF или enhanced BPF. Программы BPF могут быть написаны на языках высокого уровня, таких как Python и C++, и могут загружаться и выгружаться динамически, что делает ее мощным инструментом для мониторинга и отладки систем Linux. Другими словами, с помощью eBPF можно делать практически что угодно: от «прочесть содержимое пакета, пришедшего в сетевую карту», до «читать переписку в десктопном Telegram».
Одно из преимуществ eBPF — низкие накладные расходы. Поскольку BPF работает в пространстве ядра, он может анализировать данные без необходимости копировать их в пространство пользователя, что может значительно снизить влияние на производительность системы. Кроме того, программы eBPF могут загружаться и выгружаться динамически, что означает, что вы можете обновлять свои фильтры без перезагрузки системы. Выполнение кода eBPF гарантирует безопасный запуск в продакшн системах, так как перед загрузкой в runtime ядра, eBPF программа запускается в «песочнице» и ядро убеждается, что запуск программы не вредит работе системы.
Процесс запуска eBPF
Для запуска eBPF программы требуются две вещи: скомпилированный байткод BPF и проба, при вызове которой будет запускаться код eBPF. Проба — это флаги, маркеры, трейсы, брейкпойнты, реализованные в коде ядра, или библиотеки, с помощью которых можно получить доступ к данным в памяти, например, прочитать аргументы определенной функции.
После компиляции кода в BPF байткод, байткод загружается с помощью системных вызовов в ядро Linux. В свою очередь, ядро сначала запускает байткод в verifier для проверки BPF программы. Verifier убеждается, что программа не сломает ядро, не имеет непрерывных циклов и что программа имеет достаточные привелегии для запуска. После ядро загружает в свой рантайм BPF программу с привязкой к определенной пробе. В случае, когда триггерится проба (пришел пакет/был вызван syscall/запустилась функция), ядро копирует адресное пространство окружения в памяти, запускает BPF программу и дает доступ к скопированному адресному пространству. Таким образом, BPF программа может безопасно прочесть данные в памяти, обработать его и вывести необходимую информацию в пользовательскую программу (maps).
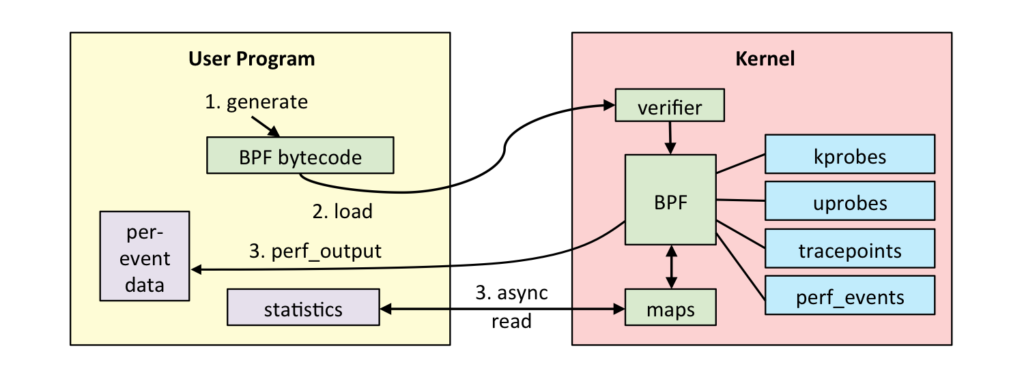
Для легкого понимания принципа работы BPF можно провести аналогию с брокерами сообщения (kafka/rabbitmq), где:
— источник (producer) — проба
— получатель (consumer) — eBPF программа
— сообщение — данные окружения, копия адресного пространства памяти объекта.
BPF программа после загрузки в ядро, будет находиться в режиме ожидания пробы (сообщения). Каждый раз, когда триггерится привязанная проба, ядро копирует окружение (память) в момент вызова этой пробы и запускает загруженную BPF программу, предоставляя доступ к этой копий окружения.
Отладка Linux с помощью eBPF
Для отладки Linux с BPF вы можете использовать как готовые утилиты на базе BPF — bcc-tools и bpftrace, так и написать свой код BPF, используя библиотеку libbcc. Для быстрого старта в освоении eBPF достаточно научиться использовать готовые утилиты bcc-tools и bpftarce, так как, по сути, 80% всех нужд в инструментах eBPF покрываются этими утилитами. Чтобы начать использовать eBPF, не обязательно уметь писать eBPF программы.
Bcc-tools — набор готовых утилит, которые устанавливаются пакетным менеджером (dnf/apt) в систему и после установки готовы к использованию «из коробки». Например, утилита execsnoop показывает новые запущенные процессы в реальном времени. Эта утилита написана на Python. Изучив исходный код, можно легко удостовериться, что данная eBPF программа использует пробу на системный вызов execve — системный вызов, отвечающий за запуск процесса.
Bpft устанавливается стандартными пакетными менеджерами. С помощью bpftrace можно написать однострочную команду, которая, например, выполняет то же самое, что и execsnoop в bcc-tools:race. Предназначен для написания однострочных BPF команд/инструкций и скриптов. Удобен для быстрой проверки гипотезы или отладки проблем и также устанавливается стандартными пакетными менеджерами. С помощью bpftrace можно написать однострочную команду, которая, например, выполняет то же самое, что и execsnoop в bcc-tools:
bpftrace -e ‘tracepoint:syscalls:sys_enter_execve { printf(«%-10u %-5d «, elapsed / 1000000, pid); join(args->argv); }’
Советы:
— показать все доступные пробы в bpftrace можно командой: bpftrace -l
— посмотреть аргументы интересующей пробы: bpftrace -vl tracepoint:syscalls:sys_enter_execve.
Плюсы и минусы BPF
Основное преимущество BPF — низкие накладные расходы, что позволяет осуществлять мониторинг и отладку системы без существенного влияния на производительность. Кроме того, поскольку BPF работает в пространстве ядра, он может предоставить более подробную информацию, чем другие инструменты отладки, работающие в пространстве пользователя.
Однако у eBPF есть некоторые ограничения. Поскольку eBPF — это виртуальная машина, она может не поддерживать все базовые аппаратные функции. Более того, программы BPF могут быть сложны в написании и отладке, особенно для новичков, незнакомых с низкоуровневым программированием.
Заключение
BPF — это мощный инструмент для отладки Linux, который может предоставить подробную информацию о производительности вашей системы. Используя bcc-tools и bpftrace, вы можете легко погрузиться в технологию eBPF и получить доступ к большому числу инструментов, который периодически дополняется и улучшается сообществом open source.
Хотя BPF имеет некоторые ограничения, низкие накладные расходы и возможность запуска в пространстве ядра делают его ценным инструментом для любого инженера DevOps. Благодаря широкому спектру поддерживаемых проб BPF может помочь вам быстро и эффективно выявить и устранить проблемы в вашей среде Linux.